
Die Datendrehscheibe als erfolgreicher Weg zur Digitalisierung mit End-to-end Business-Analytics von Mayato
Informationsaustausch über die ganze Supply Chain eines mittelständischen Lebensmittelproduzenten
-
 Dr. Marcus Dill, Geschäftsführer, Mayato
Dr. Marcus Dill, Geschäftsführer, Mayato -
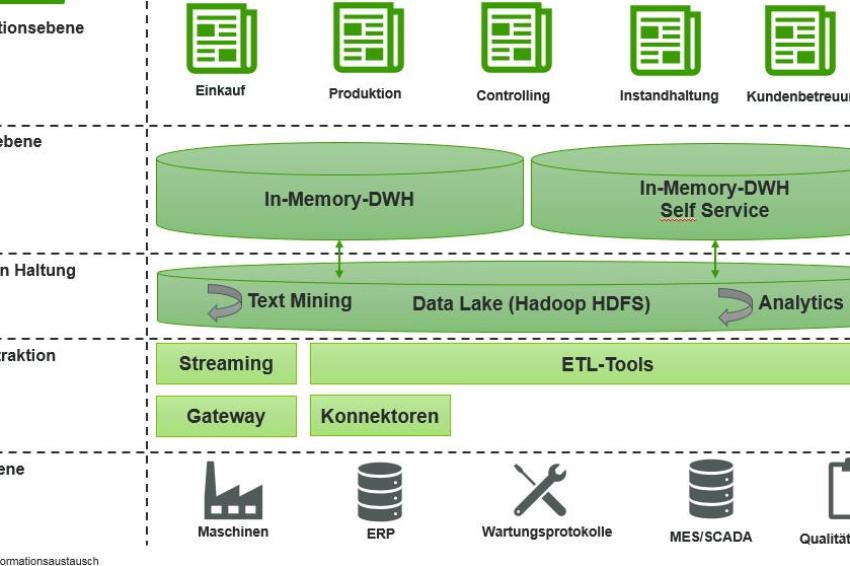 Abb.: Mögliche Architektur einer Datenplattform.
Abb.: Mögliche Architektur einer Datenplattform.
Fachleute und Digitalisierungsexperten sind sich einig: Bereits in den nächsten Jahren werden sich – bisher noch separate – Geschäftsbereiche der Unternehmen und Partner-Unternehmen übergreifend weiter vernetzen. Die Anforderungen an die Digitalisierung werden damit immer komplexer, da sie auch außerhalb der unternehmenseigenen Supply-Chain bei Kunden und Lieferanten greifen soll. Produkte, Dienstleistungen und Prozesse werden immer stärker miteinander verknüpft und bauen auf einer gemeinsamen Datenbasis auf. Doch wie lässt sich eine solch zentrale „Datendrehscheibe“ realisieren? Auf was gilt es zu achten?
Schritt für Schritt zur Digitalisierung
Als anschauliches Beispiel nehmen wir einen mittelständischen Lebensmittelproduzenten, der die erste Digitalisierungsstufe erreicht hat. Jetzt sollen neue Services entwickelt und Datenquellen aus dem Produktionsprozess angebunden werden. Für die Entscheidungsträger innerhalb der Supply Chain im Unternehmen sollen aussagekräftige Analysen und Berichte erstellt werden, um fundierte Entscheidungsgrundlagen zu schaffen. Dabei soll es u. a. möglich sein, die Mitarbeiter im Controlling über die aktuellen Kosten in der Produktion zu informieren oder den Einkauf über den tatsächlichen Materialverbrauch auf dem Laufenden zu halten.
Man möchte sich nicht mehr ausschließlich auf die Produktionsplanung verlassen, die bei jedem unvorhergesehenen Ereignis, wie z. B. dem Stillstand einer Maschine oder einer neu definierten Kapazitätsplanung, bereits veraltet ist. Darüber hinaus erhofft man sich von der besseren Informationsversorgung einen Vorteil gegenüber der Konkurrenz im Hinblick auf die Reaktionsfähigkeit bei Kunden und Lieferanten. Durch die Analyse der anfallenden Daten im Unternehmen sollen z. B. Predictive Maintenance und Predictive Quality umgesetzt werden.
Herausforderungen im Alltag
Aktuell tauschen die Bereiche Einkauf, Produktionsplanung, Produktion, Vertrieb, Controlling/Rechnungswesen, HR sowie die Entwicklung nur unzureichend Informationen aus, und die Mitarbeiter verlassen sich mehr auf ihr Bauchgefühl als auf fundierte Informationen. Hinzu kommt, dass der unregelmäßige und reaktive Informationsaustausch zu Qualitätsproblemen innerhalb der Lieferkette im Unternehmen führt. Bestellt ein Kunde unvorhergesehen Ware nach, gelangt diese Information nur verspätet an den Einkauf, was zu einem Engpass bei den Rohmaterialien führen kann.
Produktionsausfälle, Stillstände oder auch die Um- und Neuplanung der Produktion werden sehr oft nur verspätet in die Bereiche Controlling, Einkauf und Vertrieb kommuniziert. Dadurch können Kunden und Lieferanten nicht rechtzeitig informiert werden, was negative Effekte auf Absatz und Produktionsplanung hat. Darüber hinaus wird die Steuerung der Prozesse im Controlling erschwert, da sich Planzahlen ändern und diese Änderungen nur lückenhaft kommuniziert werden. Neben den genannten Problemen gibt es noch eine Reihe weiterer Schwierigkeiten, die meist mit fehlender oder verspäteter Kommunikation von Informationen zusammenhängen.
Prozessumstellung anhand eines Beispiels
Konsequenz daraus: Die Geschäftsleitung plant die bereichsübergreifende Informationsversorgung aller Bereiche mit dem klaren Ziel, die Prozesse zu optimieren. Nach dem Motto „Think big, act small” soll exemplarisch ein Prozess umgestellt werden. Um eine möglichst breite Akzeptanz in allen Bereichen des Unternehmens zu erreichen, wurde ein Prozess ausgewählt, der die meisten Abteilungen im Unternehmen tangiert. Dabei handelt es sich um eine Kundenbestellung mit anschließender Beschaffung der notwendigen Rohstoffe, die Produktion der Bestellung und deren Auslieferung sowie die darauffolgende Rechnungsstellung.
Bisher lief der Prozess vereinfacht ab:
- Der Kunde gibt eine Bestellung auf.
- Aufgrund der verfügbaren Lagermengen und den bekannten Produktionszeiten wird ein Liefertermin errechnet.
- Dieser Termin wird dem Controlling gemeldet und dort eine entsprechende Rechnung für diesen Termin erstellt.
- Je nach Verfügbarkeit der Rohmaterialien wird eine Meldung an den Einkauf gegeben für eventuelle Nachbestellungen.
- Der erwartete Liefertermin wird dem Kunden in der Auftragsbestätigung mitgeteilt.
- Die Bestellung wird als Produktionsauftrag erfasst und an die Produktion gegeben.
- Die Bestellung wird produziert und ausgeliefert.
Aus dem beschriebenen Prozess ergeben sich folgende Probleme:
- Die Lieferzeiten der Rohmaterialien sind als Standardwerte im ERP erfasst. Eventuelle Änderungen werden nur unzureichend an die Vertriebsabteilung und die Produktion kommuniziert. Bei Verzögerungen muss die Produktionsplanung umgestellt und der Kunde über die Änderung informiert werden. Dies geschieht meist verspätet.
- Durch die gängige Praxis der Rechnungsstellung für den Liefertermin muss eine entsprechende Änderung dem Controlling übermittelt werden. Geschieht dies nicht, erhalten Kunden Rechnungen für verspätete Lieferungen zu früh. Dies kann zu Verärgerung auf Kundenseite führen.
- Verzögerungen in der Produktion oder Maschinenstillstände verschieben den Liefertermin und verändern die Soll-Kosten des Auftrags. Diese Informationen gelangen aktuell entweder nur sporadisch oder aber verspätet in die jeweiligen Abteilungen. Dies führt einerseits zu verärgerten Kunden, andererseits kann die Controlling Abteilung die Kosten nicht anpassen, wodurch falsche Annahmen für die kalkulatorischen Kosten eines solchen Auftrags entstehen.
- Qualitätsprobleme und Maschinenstillstände werden in der Produktion zwar schnellstmöglich behoben, doch die Analyse dieser Probleme ist nur unzureichend. Ein „Lessons Learned“ für die Wartung oder die Produktentwicklung findet nur unzureichend oder gar nicht statt.
- Die oben beschriebenen Herausforderungen finden sich in gleicher oder ähnlicher Form bei vielen Unternehmen wieder. Daher ist der folgende Lösungsansatz auf viele Unternehmen und Branchen übertragbar.
Um die Kommunikation zwischen den einzelnen Abteilungen zu verbessern und schneller auf geänderte Prozessabläufe reagieren zu können, bietet sich eine Datenplattform, auf die alle Akteure Zugriff haben, als geeignete Lösung an. Auf einer solchen Plattform werden alle prozessrelevanten Daten aus den jeweiligen Systemen der Abteilungen erfasst und ausgewertet. Die Auswertungen werden wiederum den einzelnen Bereichen für deren Entscheidungen zur Verfügung gestellt. Die Abbildung zeigt den möglichen Architekturansatz einer solchen Datenplattform und ist hier als best-of-breed Lösung aufgebaut.
Schauen wir uns den Aufbau allgemein und für unser Beispielunternehmen an:
Datenebene
Die Datenebene beschreibt mögliche Datenquellen – auch Sensordaten, die für den Prozessfluss relevant sein können. Ein besonderes Augenmerk sollte auf die Qualität der Daten gelegt werden. Die Daten müssen im Vorfeld bereinigt und auf ihre Konsistenz geprüft werden. In unserem Beispiel sollen auf dieser Ebene Objekte aus dem ERP-System und eine Produktionsanlage angebunden werden.
Datenextraktion
In der Extraktionsschicht kommen ETL- und ELT-Werkzeuge zum Abziehen von Daten aus den jeweiligen Schnittstellen oder Gateway zum Einsatz. Im konkreten Beispiel sollen in der Extraktionsebene zunächst zwei Quellsysteme angebunden werden. Zum einen wird das ERP-System mithilfe des Extraktionstools und des ETL-Tools angebunden. Zum anderen erfolgt die Anknüpfung einer Produktionsanlage über ein Gateway von HMS.
Rohdaten-Haltung
Bei der Datenhaltung ist es oftmals sinnvoll, einen „Cold-Warm Data“ Ansatz anzuwenden. In der beschriebenen Architektur wird dies mit einer sogenannten Rohdatenschicht realisiert, die sämtliche Daten durchlaufen und in der die Cold-Data langfristig abgelegt werden. Hadoop ist für die Rohdaten ganz besonders gut geeignet, da es einerseits kostengünstig als Langzeitspeicher zur Verfügung steht, andererseits aber auch vielfältige Möglichkeiten für die Datenverarbeitung und Analyse bietet. Ein weiterer Vorteil einer solchen Rohdatenhaltung ist, dass die Daten vorerst gelagert werden können, um für spätere Zwecke schneller zur Verfügung zu stehen. Darüber hinaus sind bereits Analysen im Data Lake möglich.
Durch die breite Datenbasis und die Unabhängigkeit vom operativen Prozess können komplexe Algorithmen angewandt und sehr gute Ergebnisse in Bezug auf Prediction und Textmining erzielt werden. Die abgezogenen Daten werden im vorliegenden Beispielunternehmen in Hadoop langfristig abgelegt und für die Weiterverarbeitung in der In-Memory Datenbank vorbereitet. Die Daten werden nach bestimmten Kriterien in die darüberliegende Analyse-Ebene kopiert. Darüber hinaus finden bereits erste Anreicherungen mit Stammdaten, Analysen und Aggregationen statt.
Analyse-Ebene
In dieser Ebene befinden sich z. B. in einer relationalen oder einer NO-SQL Datenbank Daten, die für Analysen und Visualisierungen benötigt werden. Auch die Verwendung von In-Memory Datenbanken birgt großes Potenzial für schnelle und zielgerichtete Analysen. Der Einsatz von Analyse- und Textmining-Werkzeugen ist ebenfalls möglich. In dieser Ebene werden die Informationen generiert, die den tatsächlichen Mehrwert darstellen. Hier finden sich Daten zu getätigten Bestellungen, Rohstoffverfügbarkeiten oder Produktionskapazitäten. Außerdem werden dem System Produktionsausfälle der angebundenen Anlage gemeldet. Die tatsächlich produzierte Menge wird regelmäßig in festgelegten Zeitabständen mit der Auftragsmenge verglichen und analysiert, ob das an den Kunden kommunizierte Auftragsdatum eingehalten werden kann.
Darüber hinaus werden die Ist-Kosten des Auftrags mit den tatsächlich verursachten Kosten aufgrund von Stillständen und anderen Faktoren errechnet und dem Controlling zur Verfügung gestellt. Auch die Informationen des Einkaufs werden im System eingelesen und entsprechend berücksichtigt.
Durch die Auswertung aller relevanten Auftragsinformationen können Liefertermin und Kosten des Auftrags sehr genau berechnet und zeitnah an die Stakeholder im Unternehmen und an den Kunden kommuniziert werden.
Informations-Ebene
In dieser Ebene werden die notwendigen Informationen als standardisierte Reports oder individuell für die einzelnen Abteilungen bereitgestellt. Darüber hinaus haben die Stakeholder die Möglichkeit, auf Daten aus der Analyseebene zuzugreifen und sich eigene Reports zu generieren. Im Beispiel bedeutet dies: Das Controlling kann die Informationen über die tatsächlichen Maschinenzeiten und damit die Kosten für die Herstellung eines Produktes für nachstehende Kalkulationen nutzen. Die Wartungsabteilung, die nicht direkt im oben beschriebenen Prozess involviert ist, kann dennoch die Informationen über Maschinenausfälle nutzen, um die Wartungshäufigkeit anzupassen oder langfristig Predictive Maintenance einzuführen.
Fazit
Die Digitalisierung bietet enormes Potenzial, um die Prozessqualität in Unternehmen und die Zufriedenheit der Kunden zu steigern. Entscheidend dabei: Eine unternehmensweite Strategie mit lokalen Projekten und Erfolgen. Wer mit Projekten startet, die relativ schnell zu implementieren sind und einen vorzeigbaren Nutzen haben, erhöht seine Erfolgschancen signifikant und arbeitet deutlich wirtschaftlicher. Das Motto muss lauten: „Think big, start small“.
Anhand der dargestellten Lösung lassen sich die horizontale wie auch die vertikale Skalierbarkeit eindeutig belegen. Zum einen können unterschiedliche Prozessebenen im Unternehmen von der Datenerzeugung bis hin zur Entscheidungsebene verknüpft werden, zum anderen lässt sich die gesamte Supply Chain im Unternehmen vernetzen.
Wagt man einen Ausblick, so werden automatisierte und sich selbst steuernde Prozesse in Unternehmen weiter zunehmen. Firmen, die bereits heute wichtige Digitalisierungsschritte vollziehen, werden in Zukunft von ihren Erfahrungen profitieren. Die Einführung einer zentralen Datenplattform im Unternehmen und – durch die Einbindung von Kundensystemen – auch darüber hinaus, gewährleistet den Informationsaustausch innerhalb der gesamten Supply Chain und ist damit ein großer Schritt in die richtige Richtung.
Contact
mayato GmbH
68161 Mannheim




