
Echtheits- und Qualitätsscreening von Lebensmitteln
NMR, oder was sonst?
-
 © slawek_zelasko - stock.adobe.com
© slawek_zelasko - stock.adobe.com
Die Verfälschung von Lebensmitteln ist vermutlich so alt wie die Menschheit. In den letzten Jahren gab es jedoch dramatische Fälle von Lebensmittelbetrug, von denen ganze Branchen betroffen waren. Verfälscher sind heute in der Lebensmitteltechnologie und -analytik bewandert. Mit Standardmethoden lassen sich solche Fälschungen nicht aufdecken. Daher werden zunehmend nicht zielgerichtete Analysemethoden eingesetzt, um Marker für Verfälschungen aufzuspüren. Unter den vielen Analysetechnologien hat die NMR in den letzten Jahren wichtige Beiträge geleistet. Es gibt jedoch auch kritische Berichte, die den NMR-Ansatz in Frage stellen, da in der Öffentlichkeit zunehmend über scheinbar falsche Ergebnisse diskutiert wird. Dieser Artikel gibt einen kritischen Überblick – der weitgehend unabhängig der verwendeten Technologie ist.
KI-gestützte, nicht zielgerichtete analytische Ansätze
Lebensmittelbetrug, auch als wirtschaftlich motivierte Verfälschung (economically moti-vated adulteration, EMA) [1] bezeichnet, ist eine latente Bedrohung für die Lebensmittelindustrie. EMA betrifft nicht nur die Verbraucher, sondern kann ganze Branchen in Mitleidenschaft ziehen, wie der Pferdefleischskandal gezeigt hat. Der Betrug äußert sich in einem Unterschied zwischen den Angaben auf dem Etikett eines Lebensmittels und seinen tatsächlichen Eigenschaften. Ein grundsätzliches Problem bei der Echtheitsprüfung besteht darin, dass die Methoden zur Verfälschung von Lebensmitteln oft unbekannt sind oder – u. a. aufgrund von Verbesserungen in der Analysetechnik – von den Fälschern recht schnell geändert werden.
Hier kommen die nicht zielgerichteten Ansätze ins Spiel und entfalten ihre Stärke beim Screening auf Verfälschungen und Qualitätsmängel [2]. In den meisten Fällen ist ein Ansatz gemeint, bei dem eine analytische Technologie wie NMR, LCMS, IR usw. verwendet wird, um analytische Merkmale zu extrahieren, die Gruppen von Proben, wie z. B. echte und verfälschte (oder Herkunftsländer oder Sorten usw.), unterscheiden. Auf diese Weise können neue Marker sehr effizient entdeckt werden. Basierend auf dieser neuen Grundlage können nun neue Proben mit den (neu) etablierten Markern auf Korrelation mit den Referenzdaten getestet werden, dass heißt die neue Analyse ist in der Tat zielgerichtet. Es ist jedoch auch möglich, echte, nicht zielgerichtete Tests mit neuen, unbekannten Proben durchzuführen [3]. Zu diesem Zweck ist es notwendig, einen Referenzdatensatz zu erstellen, der ein Normal darstellt, mit dem neue Proben verglichen werden können (Abb. 1).
Die Auswertung der generierten Daten erfolgt typischerweise mit statistischen Methoden [4], die dem Bereich des maschinellen Lernens und der KI zugeordnet werden. Da es sich um einen vergleichsweise neuen Bereich in den analytischen Wissenschaften handelt, wirft die Anwendung mangels umfangreicher Erfahrung oft kritische Fragen auf [5]. Insbesondere, wenn Proben bei wiederholten Analysen unterschiedlich eingestuft werden. Man sollte jedoch bedenken, dass keine Messung ohne Unsicherheit ist – unabhängig von Technologie und Methode. Auch bei gerichteten Analysen kann es im Wiederholungsfall zu Abweichungen kommen, insbesondere wenn das Ergebnis nahe am Grenzwert liegt. Die Beurteilung, ob eine Probe zu der einen oder anderen Gruppe gehört, z. B., ob sie echt oder verfälscht ist, folgt einem etwas anderen Denkmuster. Falsch oder unterschiedlich zugeordnete Proben sorgen für mehr Diskussionen als Proben, die eindeutig schwarz oder weiß sind. Allerdings – eine ordnungsgemäße Methodenentwicklung, bspw. nach DIN EN ISO/IEC 17025, vorausgesetzt – kann dies nur einen kleinen Teil der Proben betreffen.
Warum NMR für die nicht zielgerichtete Analyse?
Die oben beschriebenen Ansätze können mit vielen verschiedenen Analysetechnologien durchgeführt werden, von denen jede ihre eigenen Vor- und Nachteile hat. Es ist daher müßig, darüber zu diskutieren, welche Technologie für einen nicht zielgerichteten Ansatz am besten geeignet ist, da auch die Eigenschaften des Analyten mit zu berücksichtigen sind. Dennoch hat die NMR in den letzten 15 Jahren insbesondere bei großen Screening-Projekten [6] zur Prüfung der Echtheit von Fruchtsäften [7], Wein [8] und Honig [9, 10] erhebliche Fortschritte gebracht, die heute auch routinemäßig eingesetzt werden. Ein NMR-Fingerprint kann dann als Grundlage für die nicht-gezielte Entwicklung von Klassifizierungsmodellen, z. B. zur Unterscheidung von verfälschtem und echtem Honig, verwendet werden. Die Spektren einer Referenzsammlung können jedoch auch als Normal dienen, was auch eine wahrhaft nicht gerichtete Prüfung neuer Proben ermöglicht. Da es sich bei der NMR um eine primäre quantitative Analysetechnik handelt, können viele der im Spektrum identifizierten Substanzen auch quantifiziert werden, so dass ein für eine allgemeine Qualitätsbewertung nutzbares Inhaltsstoffprofil für die Probe erstellt werden kann. Ein und dasselbe NMR-Spektrum eines Honigs bspw., kann daher für gezielte Tests auf Verfälschung, Sorte und geografische Herkunft unter Verwendung von KI-Modellen, für nicht gerichtete Tests auf unerwartete Abweichungen vom Referenzdatensatz und für die Quantifizierung zahlreicher Verbindungen verwendet werden, von denen viele durch internationale Honigstandards [11, 12, 13] geregelt sind. NMR-Ergebnisse können oftmals direkt zum Nachweis unzulässiger Abweichungen verwendet werden, ohne dass es einer Bestätigung durch eine andere Methode bedarf. An dieser Stelle muss auch berücksichtigt werden, dass einige Verfälschungen heute sehr ausgeklügelt und möglicherweise tatsächlich nur mit einer einzigen Methode nachweisbar sind.
Interpretation der Daten
Ein wichtiger, technologieunabhängiger Teil bei der Entwicklung solcher Methoden ist der Aufbau von Datenbanken – was gleichzeitig oft Anlass zur Kritik ist, insbesondere wenn Datenbanken (und daraus abgeleitete KI-Modelle) nicht öffentlich zugänglich sind. Hierfür kann es unterschiedliche Gründe geben. Ist die Methode jedoch akkreditiert [14] und auditierbar, sind wichtige Voraussetzungen für eine breite Anwendbarkeit gegeben, insbesondere wenn Informationen über die Datenbankzusammensetzung verfügbar sind (z. B. in Produktbeschreibungen oder Prüfberichten). Wichtig in diesem Zusammenhang ist der Zweck der Methode und wie die Ergebnisse interpretiert und angewendet werden. Oft gibt es keine offiziellen Methoden und Marker für Fälschungen sind nicht immer bekannt.
Statistisches Grundlagenwissen legt nahe, dass die Zahl der Proben mit zunehmendem Anspruch an die Richtigkeit und in Abhängigkeit der Einflussfaktoren schnell steigt. Gerade Herkunftsprüfungen betreffend stellen Forderungen nach globalen bestückten Datenbanken das Aus derartiger Projekte dar. Ein pragmatisches Vorgehen unter Berücksichtigung bspw. der Hauptbeteiligten ist angezeigt.
Für die Interpretation von Echtheitsprüfungen ist in der Regel ein vertieftes Detailwissen über das Lebensmittel – oft auch über regionale Verhältnisse – erforderlich. Und es ist wichtig zu erkennen, dass es Situationen gibt, in denen eine sichere Zuordnung der Probe nicht möglich ist. Ergebnisse wie „nicht typisch“ sind zu erwarten und müssen Teil des Interpretationsspektrums bei der Echtheitsprüfung werden (Abb. 2). Das Wesen des Betrugs besteht darin, bewusst zu täuschen. Letztendlich wird die Arbeit der Betrüger immer zu Proben führen, die nicht eindeutig zu klassifizieren sind.
Analytische Ecosysteme
Wie oben gezeigt, ist der Versuch eine untersuchte Probe einer Klasse „authentisch“ oder „nicht authentisch“ zuzuordnen, nicht immer eine triviale Aufgabe. Wenn das Ergebnis nicht eindeutig ist und berechtigte Zweifel vorhanden sind, können – ja müssen – andere, zusätzliche Maßnahmen getroffen werden, wie weitere Messungen. Insbesondere die Kombination von Einzelergebnissen oder sogar die Zusammenführung von Daten aus unabhängigen Methoden für eine kombinierte Auswertung kann ein leistungsfähiges Instrument zur Auflösung von Grautönen sein. Da bspw. im internationalen Honighandel die Zahl der Verfälschungen sehr groß ist und sogar noch zunimmt, ist es in Anbetracht der Vielzahl an Fälschungsmethoden und Substitutionsmaterialien schwierig alle Arten von Verfälschungen mit einer einzigen Methode zu erfassen [15, 16]. Ein kürzlich erschienener Bericht über die Echtheitsprüfung von Honig im Vereinigten Königreich hat gezeigt, dass viele mit NMR untersuchte Honigproben sogar durch unabhängige Methoden als verfälscht bestätigt werden konnten, was die Gültigkeit der NMR-Testergebnisse unterstreicht [17]. Walker et al. legen nahe, dass ein Ansatz, der zu widersprüchlichen Ergebnissen führen könnte, nicht zu „einer gültigen übergreifenden Authentizitätsbeurteilung“ [Übersetzung durch Autor] führen kann [18].
as Beispiel Honig zeigt klar, dass angesichts einer großen Zahl an Substitutionsstoffen, für die sehr verschiedene Marker existieren, unterschiedliche Befunde für verschiedene Methoden erwartet werden müssen. Im Falle von Honig ist es daher ausreichend, wenn nur eine Technologie/Methode eine Verfälschung nachweist. Schließlich können Methodenkombinationen zu verbesserten Ergebnissen führen, wenn Einzelmethoden keine hinreichende Ergebnisqualität liefern. Dieser Ansatz wird als analytisches Ecosystem bezeichnet. Jüngste Studien zur Herkunft von Getreide (in Bezug auf Geografie, Erntejahr, Sorte usw.) und Kakao haben gezeigt, dass die Kombination unabhängiger Analysen tatsächlich ein sehr leistungsfähiges Instrument ist und Datenfusionen zu besseren Ergebnissen führen als die entsprechenden Einzelmethoden [19, 20].
Fazit
Ungerichtete analytische Ansätze haben großes Potential, insbesondere für Authentizitätsprüfungen. NMR bietet viele Vorteile, nicht zuletzt, weil gleichzeitig mit einer Analyse auch viele gerichtete Bewertungen erfolgen können. Gerade die Frage nach der Echtheit kann nicht immer zweifelsfrei beantwortet werden. Weitere Methoden, einzeln oder in Kombination, sind dann heranzuziehen. Für die Beurteilung sind alle verfügbaren Informationen, insbesondere auch der Zweck der einzelnen Methoden, mit zu berücksichtigen.
Referenzen und lange Version des Beitrages:
https://bit.ly/GIT-Schwarzinger
-
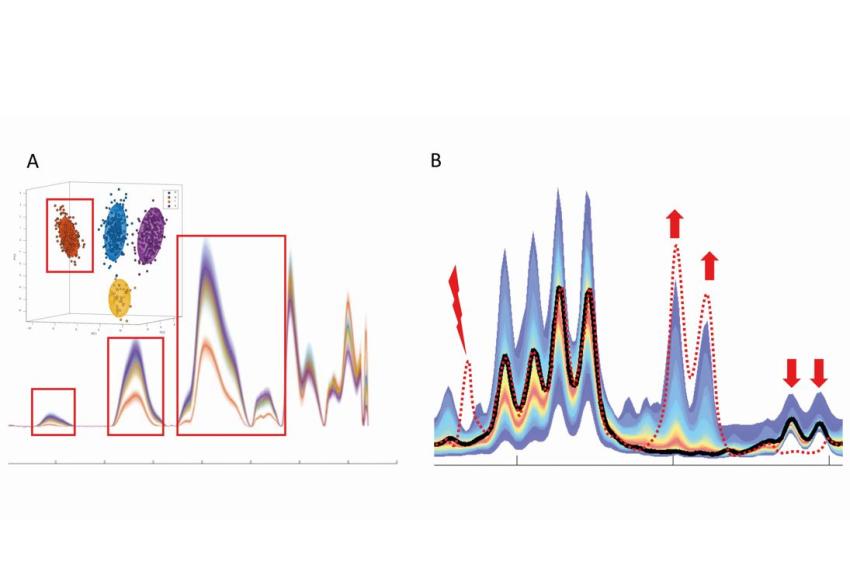 Abb. 1: Nicht zielgerichtete Entwicklung mit anschließender zielgerichteter Prüfung (A) vs. echte nicht zielgerichtete Prüfung (B), dargestellt anhand beliebiger Spektraldatensätze.
Abb. 1: Nicht zielgerichtete Entwicklung mit anschließender zielgerichteter Prüfung (A) vs. echte nicht zielgerichtete Prüfung (B), dargestellt anhand beliebiger Spektraldatensätze.
(A) zeigt die Quantilenplots der Spektren von vier Sorten eines Lebensmittels. Rote Kästchen zeigen Unterschiede an, die vorab nicht bekannt waren, nun aber in ein mathematisches Modell einfließen, das später die Zuordnung der neu analysierten Proben zu einer der vier Klassen ermöglicht. (B) Im Gegensatz dazu stellt das hier gezeigte Farbband den Quantilenplot der Spektren einer Klasse dar, z. B. von 10.000 authentischen Lebensmittelproben. Während die Probe, die das schwarze Spektrum ergibt, innerhalb der bekannten Bereiche authentischer Proben liegt, weicht die Probe, die das gestrichelte rote Spektrum ergibt, davon ab: Sie zeigt ein Signal dort, wo authentische Signale kein Signal haben (Blitz: Hinweis auf eine zuvor nicht nachgewiesene Verbindung), erhöhte Signalintensitäten (Pfeile nach oben: typisch für die Zugabe von bspw. wertgebenden Bestandteilen) und verringerte Signale (Pfeile nach unten: typisch für die Verdünnung mit einem Substituenten). Dies sind Abweichungen, die mit Ansatz A nicht unbedingt erkannt worden wären.
__________________________________________________________________________________________________________________________
-
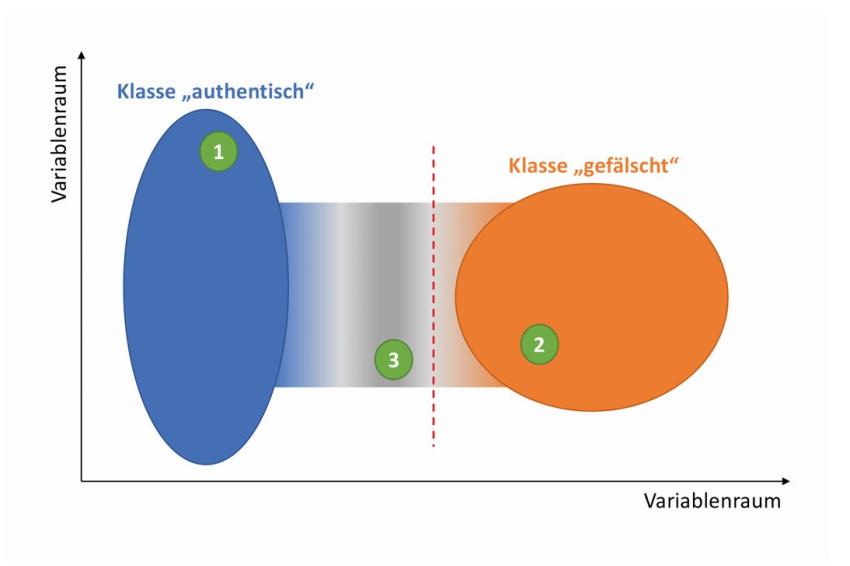 Abb. 2: Schematische Darstellung zur Verdeutlichung des Problems der Zuordnung mehrdeutiger Proben.
Abb. 2: Schematische Darstellung zur Verdeutlichung des Problems der Zuordnung mehrdeutiger Proben.
Die Ellipsen stellen den Raum dar, in dem die Proben mit einer gewissen Sicherheit, z. B. mindestens 95 %, zugeordnet werden können. Die grünen Kreise stellen Proben dar. Während die Proben 1 und 2 eindeutig – also mit hinreichender Sicherheit und Präzision – einer Klasse zugeordnet werden können (und gleichzeitig mit hoher Sicherheit aus der anderen Klasse ausgeschlossen werden können), stellt Probe 3 einen Grenzfall dar, der keiner der beiden Klassen sicher zugeordnet werden kann. Ein Konzept mit dieser Unsicherheit umzugehen ist die Einführung eines entsprechenden Entscheidungskriteriums (angedeutet durch die gestrichelte rote Linie). In diesem Fall wird eher eine verfälschte Probe als authentisch akzeptiert, als eine authentische Probe fälschlicherweise als verfälscht zu bezeichnen.
Contact
Universität Bayreuth
Universitätsstr. 30 -31
95447 Bayreuth
+49 921 55 0




